Audio Imitator: Controlling Timbre and Tempo in Video2Audio Synthesis with Audio Reference
Overview
Video-to-audio generation has made significant progress in achieving semantic consistency and temporal alignment from silent videos. However, audio contains rich stylistic attributes such as timbre and tempo that are difficult to infer from visual and textual inputs alone. While reference audio can serve as additional conditioning, it is typically treated as a holistic signal, limiting fine-grained style control. We propose AudioIM, an attribute-aware framework that explicitly models timbre and tempo as separate control factors rather than relying on holistic prompt conditioning. Dual encoders extract complementary timbre-related and tempo-related representations, which are injected through global conditioning. A masking-based training strategy enables effective latent prompt conditioning at inference.
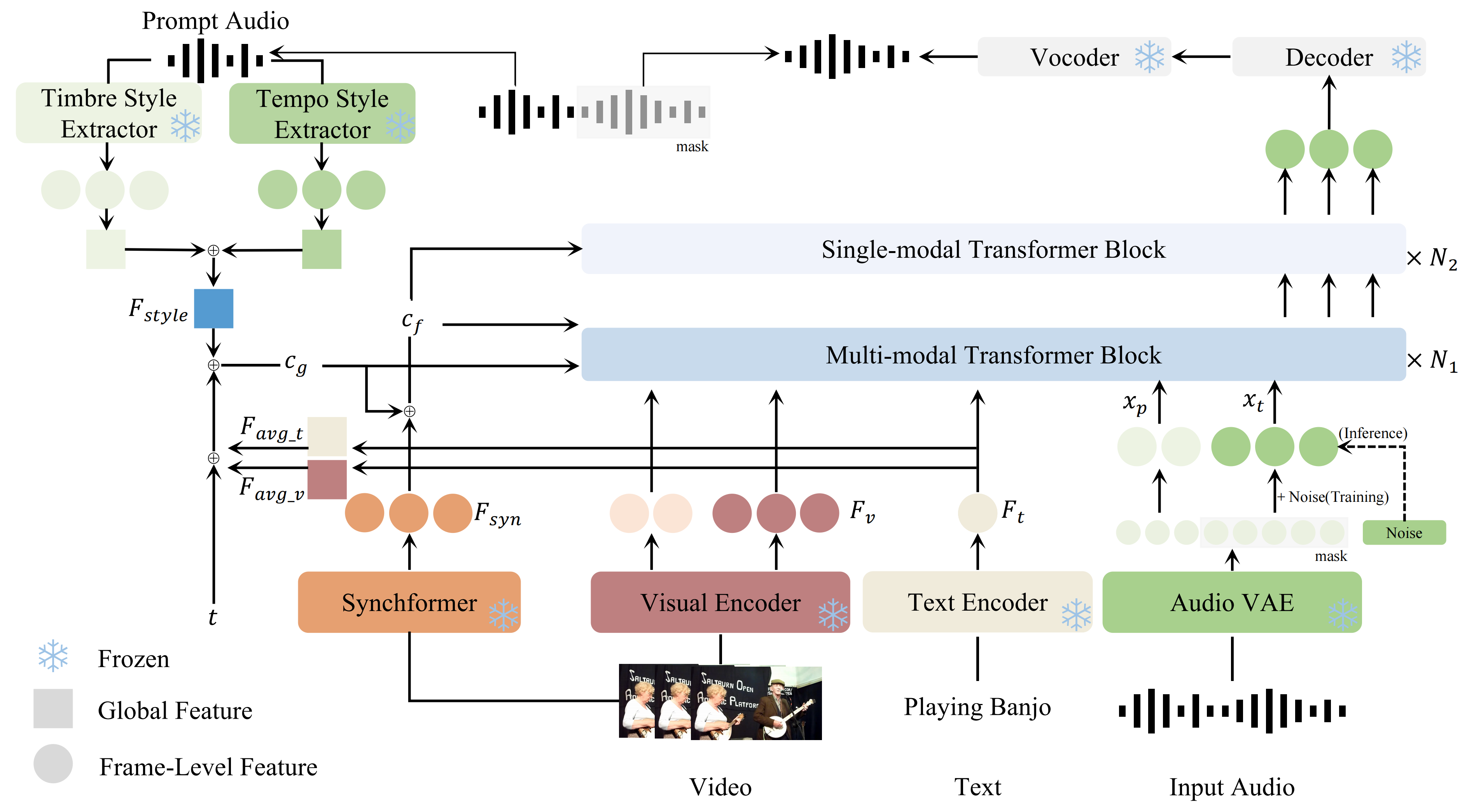
Figure 1. Overview of the proposed AudioIM framework. During training, audio latents are partially masked to enable latent-level prompt conditioning under a flow-matching objective. Reference audio is processed by dual style encoders to extract complementary timbre-related and tempo-related representations. These style features are fused and injected through global conditioning pathways, enabling attribute-aware video-to-audio generation while preserving semantic and temporal alignment.
Style Similarity between Generated and Prompt Audios
Current video-to-audio works generally condition only on visual/text content and provide little control over timbre and tempo. AudioIM produces audio with higher style similarity to the prompt and achieves strong performance on core video-to-audio tasks.
| Prompt | Ground Truth | MMAudio(Vanilla) | MMAudio w/ Prompt Masking | AudioIM w/o Style Enc | AudioIM |
|---|---|---|---|---|---|